
我是如何迁移我的博客的
温馨提示:
本文最后更新于 2022年12月09日,已超过 1,296 天没有更新。若文章内的图片失效(无法正常加载),请留言反馈或直接联系我。
写在开头
在今年初,我就打算迁移我的博客了,主要原因是ueditor编辑器不支持go代码的高亮,所以打算换,但是由于本人比较懒,同时事情又多,就耽搁了下来
此次迁移,跨度半年,实际消耗了3,4天左右,使用到了go,js,java,等语言技术栈等等,这个在后面会讲到
环境
- 服务器使用了腾讯云的2核2G4M轻量级应用服务器,3年800.找人返现了80
- 博客环境使用了oneblog https://docs.zhyd.me/ ,基于java 的springboot开发
- 使用了又拍云 https://www.upyun.com/ 做cdn加速
- 使用了宝塔+supervisord 做java进程守护管理
- 使用了go做数据迁移,nodejs做ueditor转md再转html
搭建博客
搭建博客其实挺简单的,oneblog分为了2个项目,admin,web,建库导入数据库,修改blog-core的config即可跑起来:
通过IDEA直接run,可以做本地调试,也可以通过mvn package打包放到服务器上运行:
将打包好的jar(在target目录下)放到服务器上运行
[root@VM-12-8-centos ~]# ls /www/wwwroot/newBlog/
blog-admin.jar blog-web.jar logdir_IS_UNDEFINED Upload
[root@VM-12-8-centos ~]# java -jar blog-admin.jar
[root@VM-12-8-centos ~]# java -jar blog-web.jar
运行之后,会监听 8085和8443端口,通过nginx进行反向代理:
server
{
listen 80;
server_name new.php20.cn www.php20.cn;
index index.php index.html index.htm default.php default.htm default.html;
root /www/wwwroot/newBlog;
#SSL-START SSL相关配置,请勿删除或修改下一行带注释的404规则
#error_page 404/404.html;
#SSL-END
#ERROR-PAGE-START 错误页配置,可以注释、删除或修改
#error_page 404 /404.html;
#error_page 502 /502.html;
#ERROR-PAGE-END
location / {
proxy_pass_request_body on;
proxy_pass_request_headers on;
if (!-f $request_filename) {
proxy_pass http://127.0.0.1:8443;
}
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;# 支持ws
proxy_set_header Connection "Upgrade";#支持ws
}
#PHP-INFO-START PHP引用配置,可以注释或修改
include enable-php-00.conf;
#PHP-INFO-END
#REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效
include /www/server/panel/vhost/rewrite/new.php20.cn.conf;
#REWRITE-END
#一键申请SSL证书验证目录相关设置
location ~ \.well-known{
allow all;
}
access_log /www/wwwlogs/new.php20.cn.log;
error_log /www/wwwlogs/new.php20.cn.error.log;
}
直接访问域名即可
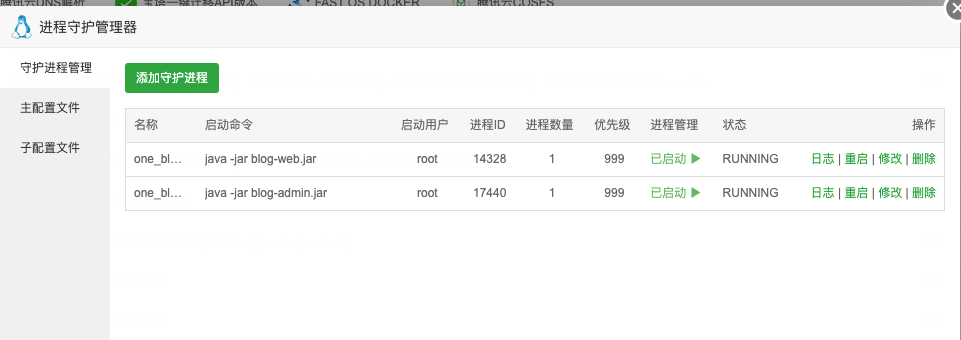
改为superior管理器
迁移博客
由于白俊遥博客和oneBlog数据库都不同,需要做数据迁移,本人使用go脚本进行迁移操作,期间使用了copilot神器实现了自动写代码: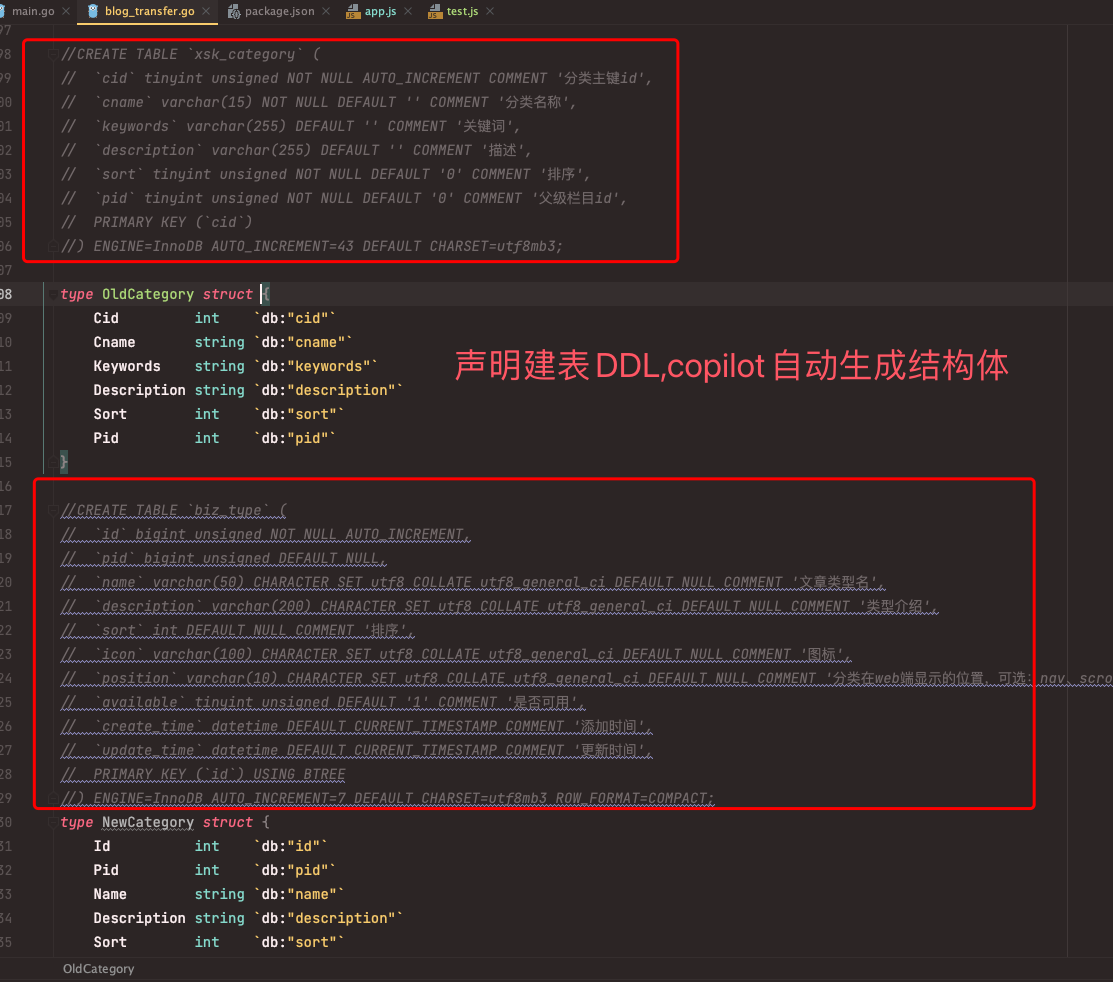
初始化sql连接
var OldDb *sqlx.DB
var NewDb *sqlx.DB
func init() {
oldDatabase, err := sqlx.Open("mysql", "213321:312321@tcp(113.111.33.11:3306)/www")
if err != nil {
fmt.Println("open mysql failed,", err)
return
}
OldDb = oldDatabase
newDatabase, err := sqlx.Open("mysql", "lll:ccc@tcp(113.111.33.113:3306)/lll")
if err != nil {
fmt.Println("open mysql failed,", err)
return
}
NewDb = newDatabase
}
脚本步骤概览
func main() {
// Your code here!
//同步分类
//syncCategory()
//////同步标签
//syncTag()
//////同步文章标签关联关系
//syncArticleTag()
//////同步文章
//syncArticle()
//////同步文章评论
//////同步友链
//syncLink()
////同步碎言碎语
//syncChat()
//将文章内容写入成html文件
//writeArticleFile()
//将md文件和html文件内容写入数据库
//readArticleFile()
//syncArticlePic()
}
同步文章
该代码也是通过copilot自动提示,然后优化
func syncArticle() {
log.Println("开始同步文章")
//获取旧的文章
oldArticle := make([]OldArticle, 0)
err := OldDb.Select(&oldArticle, "select * from xsk_article where is_delete=0")
if err != nil {
log.Fatal(err)
}
//截断旧文章表
_, err = NewDb.Exec("truncate table biz_article ")
if err != nil {
log.Fatal(err)
}
var newArticleData newArticle
//将旧文章的字段一一对应插入新的文章表
for _, v := range oldArticle {
createTime := time.Unix(int64(v.Addtime), 0).Format("2006-01-02 15:04:05")
v.Content = html.UnescapeString(v.Content)
newArticleData = newArticle{
Id: v.Aid,
Title: v.Title,
UserId: 1,
CoverImage: "",
EditorType: "we",
QrcodePath: "",
IsMarkdown: 0,
Content: v.Content,
ContentMd: "",
Recommended: v.IsTop,
TypeId: v.Cid,
Status: 1,
Original: v.IsOriginal,
Description: v.Description,
Keywords: v.Keywords,
Comment: 1,
Password: "",
RequiredAuth: 0,
CreateTime: createTime,
UpdateTime: createTime,
}
_, err = NewDb.NamedExec("insert into biz_article (id,title,user_id,cover_image,editor_type,qrcode_path,is_markdown,content,content_md,top,type_id,status,recommended,original,description,keywords,comment,password,required_auth,create_time,update_time) values (:id,:title,:user_id,:cover_image,:editor_type,:qrcode_path,:is_markdown,:content,:content_md,:top,:type_id,:status,:recommended,:original,:description,:keywords,:comment,:password,:required_auth,:create_time,:update_time)", newArticleData)
if err != nil {
log.Fatal(err)
}
//同步文章的标签
//根据文章的分类id,去获取文章的分类名,然后根据分类名关联标签表,获取标签id
var cateName string
err = OldDb.Get(&cateName, "select cname from xsk_category where cid=?", v.Cid)
if err != nil {
log.Fatal(err)
}
var tagId int
err = NewDb.Get(&tagId, "select id from biz_tags where name=?", cateName)
if err != nil {
log.Fatal(err)
}
//插入文章标签关联表biz_article_tags
_, err = NewDb.Exec("insert into biz_article_tags (article_id,tag_id) values (?,?)", v.Aid, tagId)
if err != nil {
log.Fatal(err)
}
log.Printf("文章%s同步完成\n", v.Title)
}
log.Println("文章同步完成")
}
同步文章内容样式
由于之前使用的是ueditor,生成的html格式和markdown以及各大网站规范不符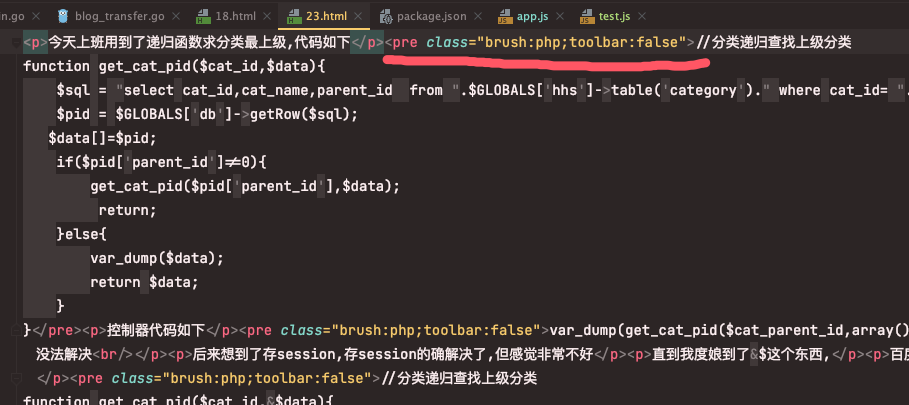
通过百度搜索,找到了一个ueditor在线转换为标准md的网站 https://www.bejson.com/convert/ueditor2markdown/
通过分析,找到了ueditor2markdown.js的相关代码:
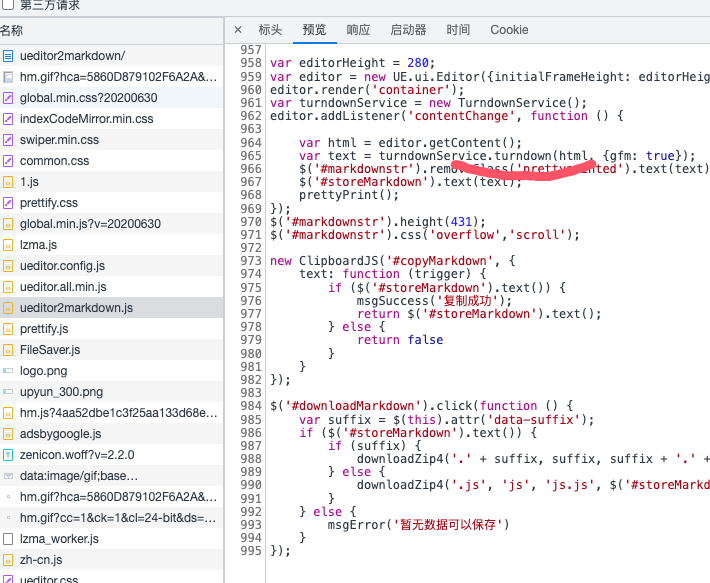
修改包的document的,改为jsdom 库实现,该代码已经开源:https://github.com/tioncico/ueditor2markdown
修改步骤为:
先通过go,将ueditor html代码写入到文件
func writeArticleFile() {
path := "./file/oldFile"
//创建路径
err := os.MkdirAll(path, os.ModePerm)
if err != nil {
log.Fatal(err)
}
//读取文章数据
article := make([]newArticle, 0)
err = NewDb.Select(&article, "select * from biz_article")
if err != nil {
log.Fatal(err)
}
//遍历文章数据,将content写入文件
for _, v := range article {
fileName := strconv.Itoa(v.Id) + ".html"
file, err := os.Create(path + "/" + fileName)
if err != nil {
log.Fatal(err)
}
_, err = file.WriteString(v.Content)
if err != nil {
log.Fatal(err)
}
}
}
nodejs读取文件,将html文件转为markdown,再转为标准html文件:
// 引入 markdown-it 库
TurndownService = require('./ueditor2markdown.js');
// 创建 markdown-it 实例
// 引入 fs 模块
var fs = require('fs');
var path = "../file/oldFile"
// 遍历文件夹,读取所有文件
var files = fs.readdirSync(path);
files.forEach(function (item, index) {
var oldPath = path + '/' + item;
var newPath = "../file/newFile" + '/' + item.replace(/\.html$/, '.md');
var content = fs.readFileSync
(oldPath, 'utf-8');
var turndownService = new TurndownService();
var markdown = turndownService.turndown(content);
markdown = handleMd(markdown);
fs.writeFileSync(newPath, markdown);
newHtmlPath = "../file/newFile" + '/' + item;
var md = require('markdown-it')();
var result = md.render(markdown);
fs.writeFileSync(newHtmlPath, result);
});
function handleMd(str) {
// 创建一个新的正则表达式,用于匹配连续 4 个 "=" 符号
var regex = new RegExp(/={4,}/);
// 查找字符串中是否存在连续 4 个 "="
var result = str.match(regex);
// 如果存在,则按行分割字符串
if (result) {
var lines = str.split("\n");
// 遍历每一行,找到连续 4 个 "=" 的行
for (var i = 0; i < lines.length; i++) {
var line = lines[i];
// 如果当前行包含连续 4 个 "=",则获取上一行的文字
if (line.match(regex)) {
lines[i] = line.replace(/=/g, "-");
var index = i - 1;
var previousLine = lines[index];
if (previousLine === "") {
lines.splice(index, 1);
// lines[index] = "";
// index--;
// previousLine = lines[index];
}
// 在文字前面增加 "# " 字符串
// previousLine = "# " + previousLine;
// 替换原来的行
// lines[index] = previousLine;
}
}
str = lines.join("\n");
}
// 输出修改后的字符串
return str;
}
golang将文件读取,更新到新数据库的md,html字段:
func readArticleFile() {
var err error
path := "./file/newFile"
//获取数据库中文章的id
article := make([]newArticle, 0)
err = NewDb.Select(&article, "select id from biz_article")
if err != nil {
log.Fatal(err)
}
//遍历文章id,读取文件内容,更新数据库
var htmlContent []byte
var mdContent []byte
for _, v := range article {
htmlFileName := strconv.Itoa(v.Id) + ".html"
//简单读取文件内容
htmlContent, err = ioutil.ReadFile(path + "/" + htmlFileName)
if err != nil {
log.Fatal(err)
}
mdFileName := strconv.Itoa(v.Id) + ".md"
//简单读取文件内容
mdContent, err = ioutil.ReadFile(path + "/" + mdFileName)
if err != nil {
log.Fatal(err)
}
//更新数据库
_, err = NewDb.Exec("update biz_article set content=?,content_md=? where id=?", string(htmlContent), string(mdContent), v.Id)
if err != nil {
log.Fatal(err)
}
}
}
整理博客配置项,优化博客的路由兼容
这个比较简单,不做额外说明
引入highlight 高亮代码
这个比较简单,不做额外说明
整个博客迁移完成
正文到此结束
- 本文标签: 服务架构
- 本文链接: https://www.php20.cn/article/404
- 版权声明: 本文由仙士可原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐

近期评论
-
来自: 留言板
-
来自: 如何策划一个模拟经营类的文字游戏
-
来自: 留言板
-
来自: 留言板
-
来自: 留言板
