详解GMP调度器
进程/线程/协程
单进程->多进程
在早期的单进程操作系统中,计算机只能一个任务一个任务的进行处理,任务完成之后才可以进行下一个任务处理
这就出现了一个情况:
- 当进程阻塞时,计算机的cpu资源就暂停浪费掉了
- 任务1需要耗时1小时,任务2只需要耗时10分钟,但是只能等到任务1完成之后才能运行任务2
所以,根据这个情况,优化成了多进程并发能力:
- 当进程阻塞时,自动切换到下一个进程去运行,等到进程不阻塞时再回去执行
- 当进程执行到一定时间时,切换到另一个进程去执行,交替执行
由于cpu执行速度很快,1秒中可能切换进程好几千次,这样看上去就是2个进程在同时运行.
这个多进程切换的逻辑,就是 进程调度器
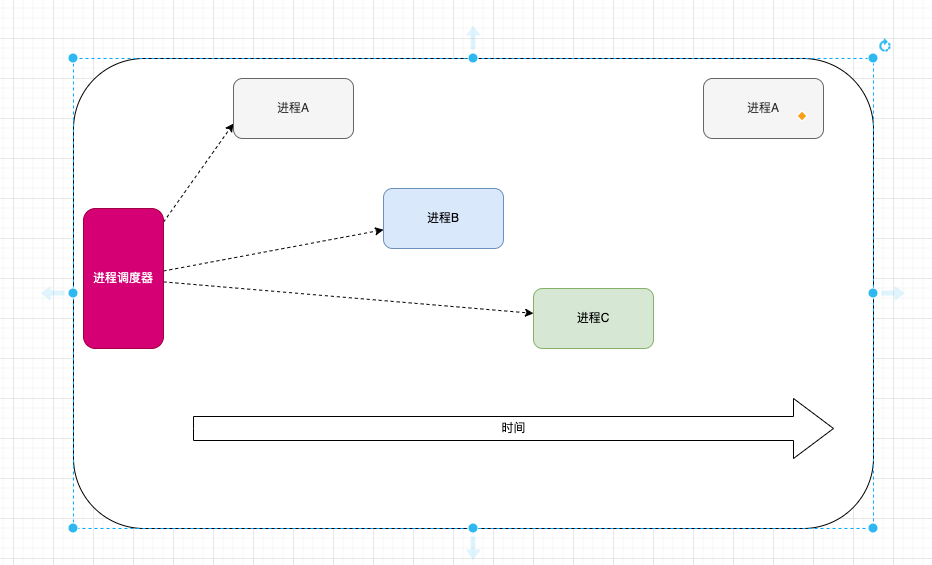
进程调度器的作用就是在多个进程运行时,切换不同的进程去运行.
当进程阻塞时,及时将cpu资源让出给其他进程
但是,进程调度器并不是没有损耗的,当进程切换时,需要保留进程上下文,切换进程虚拟内存空间等等,同时进程创建,销毁都是需要耗费资源的
多进程下,如果是多个cpu,则可以同时运行多个任务,这个同样需要进程调度器进行调度
多进程->多线程
多进程中,每个进程的内存空间相互独立,有着独立的进程信息,假设你的进程需要获取100个网站的信息,需要怎么做?
你可能想到了单进程时代的情况:需要一个网站一个网站的获取,如果第一个网站访问比较慢,那就阻塞住了,导致这个进程的执行效率会比较低,解决这个的方法有2种:
1:创建100个进程,让每个进程去获取1个网站的信息
2:创建100个线程,让cpu去调度多线程
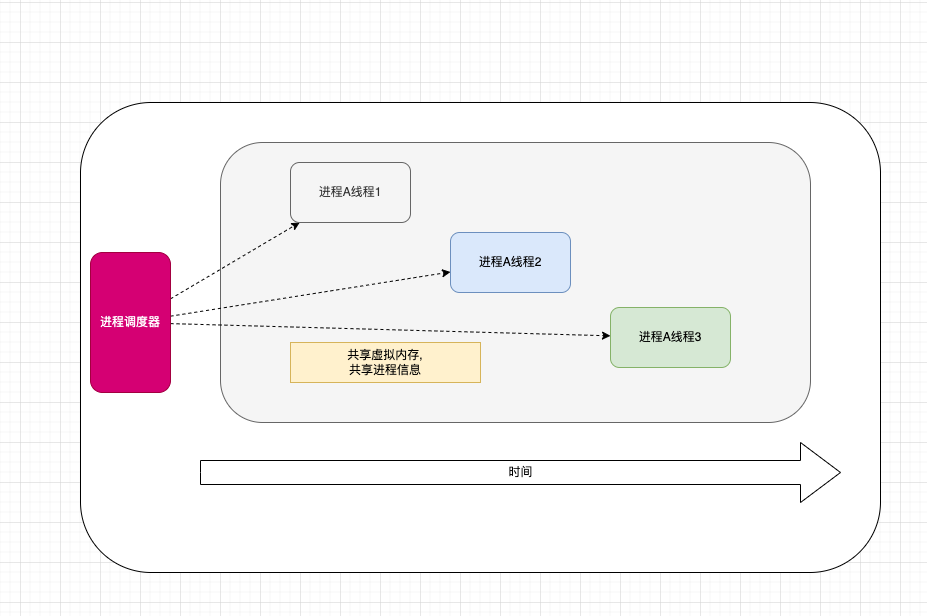
线程是cpu的最小执行单位,多个线程共享进程的虚拟内存空间,切换消耗较少,同时使得一个进程能利用到多个cpu
线程创建,销毁,切换,线程都比进程的消耗少
多线程->多协程
由上我们知道,线程是cpu执行的最小单位,也就是说,线程的切换,执行的调度器依然是操作系统在调度的,我们称之为 内核态
在多线程编程中,会有各种并发问题,例如线程锁,同步竞争,竞争冲突等问题
再后来,发现了 用户态线程 ,也就是协程
协程是在用户态,也就是基于线程的用户态子例程,操作系统并不知道有协程的存在,操作系统只知道它运行了一个内核态的线程
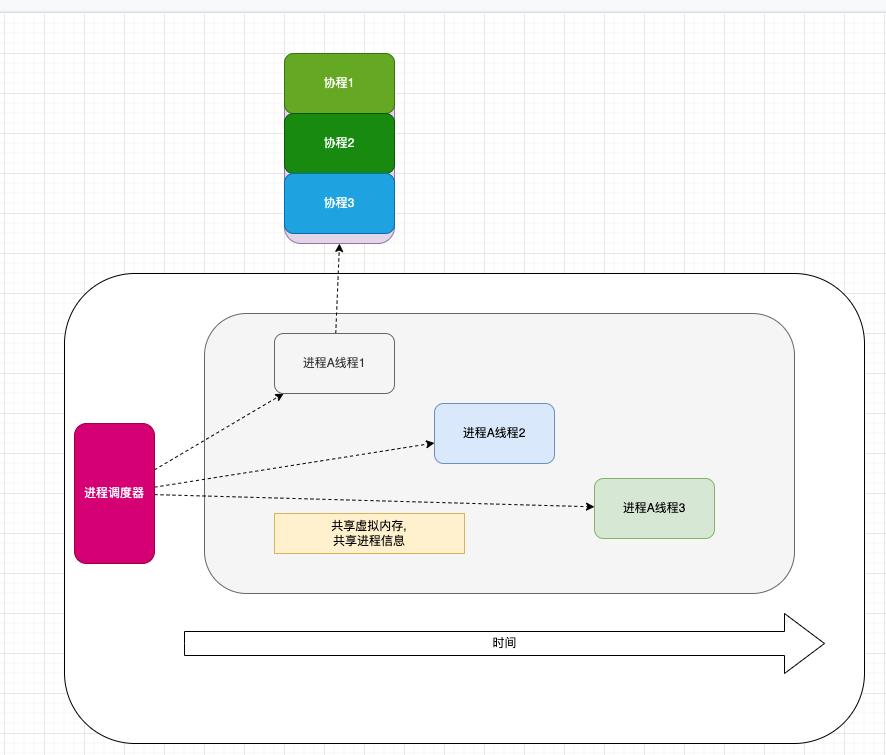
通过这个,我们知道了它们互相之间的关系
关系
- 进程与线程之间为1:N关系
- 线程与协程之间为1:N关系
- 操作系统的最小调度单位为
线程 - 线程可以运行协程
在GMP中,线程与协程之间的关系为M:N,协程A可能会在线程1执行,也可能下一次在线程2执行
GMP调度模型
在go语言中,主要分为3个对象:M(thread),G(goroutine),P(processor)
- M(thread) 线程,
- G(goroutine) go的协程
- P(processor) 处理队列
大概模型如下: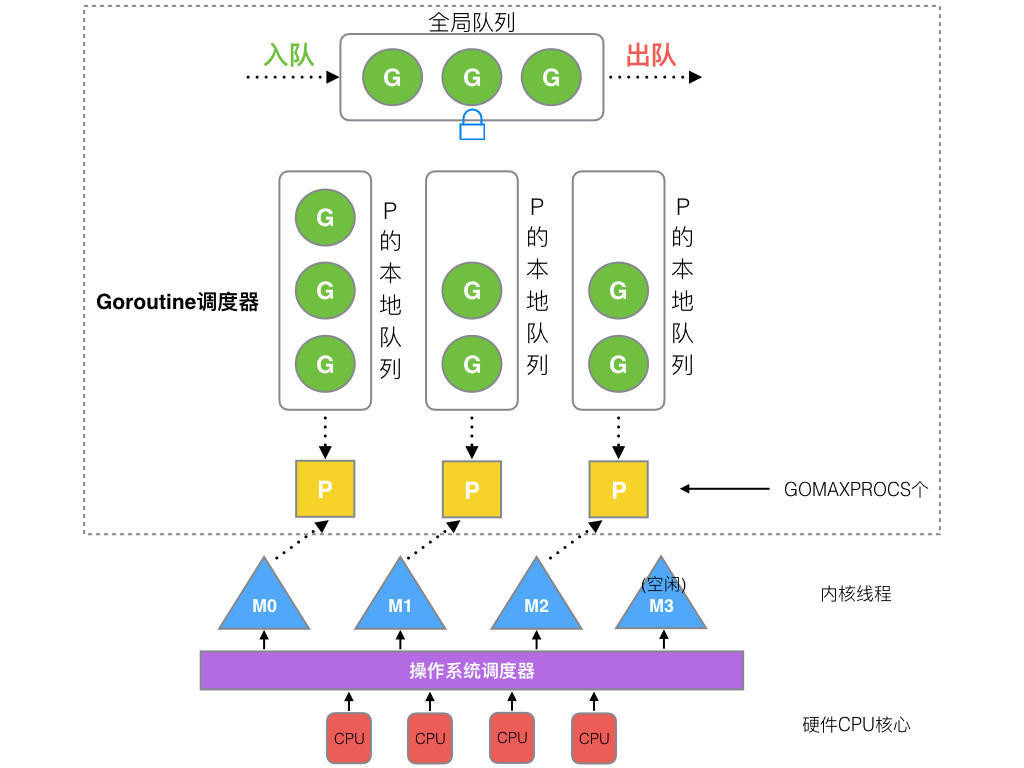
- 全局队列(global queue) ,存放等待运行的G
- P队列,存放等待运行的G,但是只能存256个,在创建G之后,优先进入P队列,当队列满了时会将队列一半的G移动回全局队列
- P队列的数量,在程序启动的时候就创建,最多有GOMAXPROCS 个(默认为cpu线程数)
- M运行线程,线程会去绑定一个P去执行G的任务,当P为空时,M会尝试从全局队列(获取其他P队列)拿到G放到P队列执行.
关于GMP数量的问题
G
协程数量在理论上是无限的,每个协程需要占用大概4kb的内存,只要内存足够可以一直创建,只要使用go关键字即可创建
M
M在有空闲P需要执行时就会创建,每个P都得绑定一个M,如果一个M阻塞住了,则会创建一个新的线程来运行P
M的最大数量默认是1万,但实际上不会出现这么多的数量.
P
在程序运行获取到最大数量n之后,运行时就会创建n个P
协程调度流程
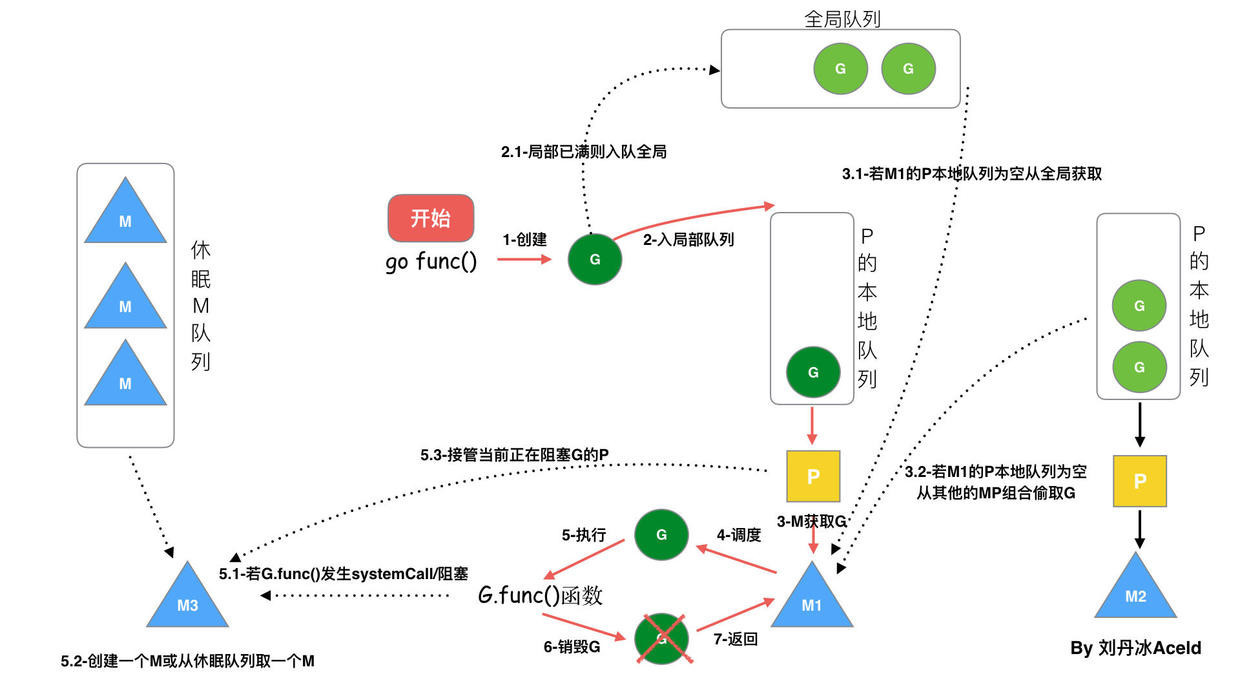
- 我们通过go 关键字创建一个goroutine
- 新创建的G会优先保存到P队列中,只有满了才会放到全局队列
- G只能进入P队列,并且被M绑定之后才能通过M运行
- 当M执行某一个G阻塞时(syscall或者其他阻塞),则该绑定的P(连同P队列的G)会被摘除(detach),获取一个新的空闲M线程去绑定这个P(如果没有空闲的,则创建一个新M线程).绑定P之后继续执行P队列上的G
- 当这个阻塞的G在M中调用结束之后(没有阻塞之后),由于该M已经没有绑定P了,所以这个G将加入到全局队列,M将变成休眠状态加入到空闲线程
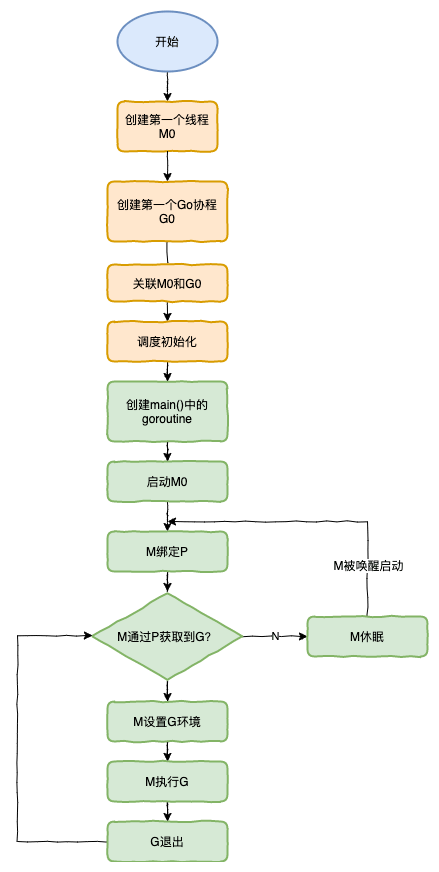
G0和M0
M0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0
G0 是每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
代码查看
package main
import (
"fmt"
)
func main() {
fmt.Println("hello world")
}
这个是最简单的hello world,过程如下:
- runtime 创建最初的线程 m0 和 goroutine g0,并把 2 者关联。
- 调度器初始化:初始化 m0、栈、垃圾回收,以及创建和初始化由 GOMAXPROCS 个 P 构成的 P 列表。
- 示例代码中的 main 函数是 main.main,runtime 中也有 1 个 main 函数 ——runtime.main,代码经过编译后,runtime.main 会调用 main.main,程序启动时会为 runtime.main 创建 goroutine,称它为 main goroutine 吧,然后把 main goroutine 加入到 P 的本地队列。
- 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到 main goroutine。
- G 拥有栈,M 根据 G 中的栈信息和调度信息设置运行环境
- M 运行 G
- G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到 main.main 退出,runtime.main 执行 Defer 和 Panic 处理,或调用 runtime.exit 退出程序。
通过trace 查看分析
package main
import (
"fmt"
"os"
"runtime/trace"
)
func main() {
//创建trace文件
f, err := os.Create("trace.out")
if err != nil {
panic(err)
}
defer f.Close()
//启动trace goroutine
err = trace.Start(f)
if err != nil {
panic(err)
}
defer trace.Stop()
//main
fmt.Println("Hello World")
}
先运行一下
go run main.go
运行后将生成trace.out文件
再通过go tool查看trace:
(venv) (base) tioncico@appledeMacBook-Pro test % go tool trace trace.out
2022/12/14 15:54:32 Parsing trace...
2022/12/14 15:54:32 Splitting trace...
2022/12/14 15:54:32 Opening browser. Trace viewer is listening on http://127.0.0.1:57539
打开网址http://127.0.0.1:57539/trace 即可查看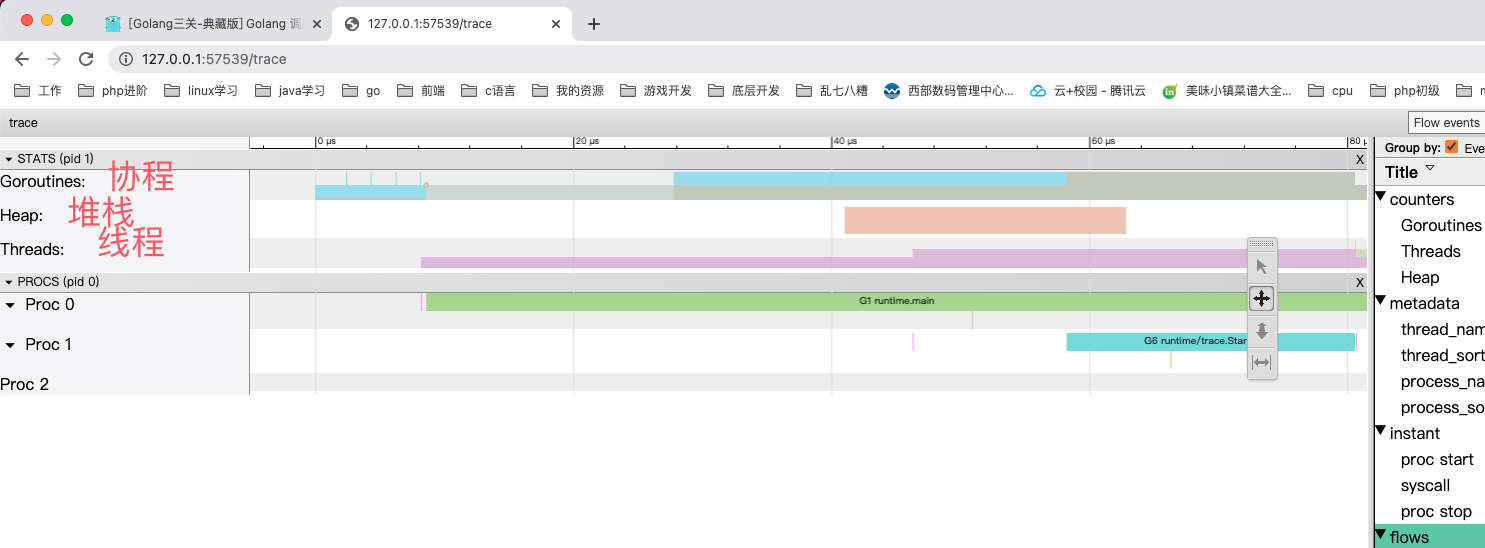
- 本文标签: 编程语言 go
- 本文链接: https://www.php20.cn/article/408
- 版权声明: 本文由仙士可原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐

相关文章
近期评论
-
来自: 留言板
-
来自: 如何策划一个模拟经营类的文字游戏
-
来自: 留言板
-
来自: 留言板
-
来自: 留言板
