一文入门kafka
什么是kafka
Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统,
使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点.
总而言之,kafka是一个消息队列中间件
kafka特点
kafka具有高吞吐量,内置分区,消息副本,高容错特性,分布式
- 高吞吐量,虽然是磁盘存储数据库,但是使用了各种优化,使其能够支持高并发吞吐
- 内置分区,对消息进行分区存储,增加并发
- 消息副本,分布式形式的消息副本,充分对消息进行负载均衡
- 高容错,采用了raft(之前使用的是zookeeper)分布式集群选举算法,宕机后自动重新选举,日志恢复
应用场景
日志聚合
通过日志采集器, 将日志采集到kafka消息队列,由日志处理应用进行消费
用户行为记录
用户不同的行为发布到不同的主题中心,分别被不同的行为处理器消费处理
异步处理(削峰填谷)
将用户请求写入消息队列,进行异步的消费处理
消息通信
IM可通过kafka实现消息通讯,群聊订阅
kafka 架构
kafka 主要角色有3个, producer(生产者),broker(代理者,kafka服务),consumer(消费者).
主要架构图如下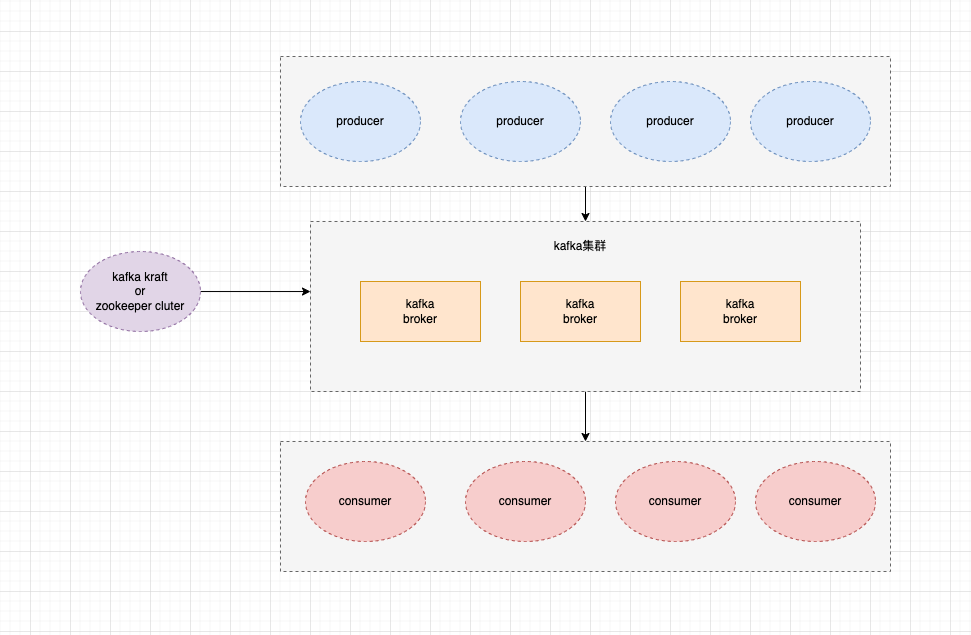
在kafka中,由生产者生产消息发送到kafka服务,然后consumer使用pull模式拉取kafka服务存储的消息
在2.8版本之后,kafka除了支持zookeeper实现分布式集群外,额外增加了kraft模式处理集群,可以抛开zookeeper进行运行了
kafka 基本术语
topic 主题
在消息订阅情况下,kafka将消息进行分类,每个分类称为 topic (主题),生产者和消费者都根据topic进行推送消息和拉取消息
partition 分区
由于,kafka是使用文件存储的,为了提高吞吐量,topic可以分区为多个partition,每个分区都可以独立运行在不同的broker进行处理,同样可以并发的将相同topic的消息写入到不同的分区,消费者也可以并发的从不同的分区读取消息
没有配置分区的情况下,topic的分区数为1,分区只有一个:0
segment 段
由于kafka的消息是不断的追加到文件中的,为了避免一个文件过大,导致数据管理难度上升,当消息文件到达一定的大小后(比如1G),则开始文件分段
文件分段后,可以更好的删除过期的消息
Producer 生产者
消息的发布者,由程序员自身的业务服务实现,在消息发送前,需要配置消息的topic 和消息的分区,比如go kafka客户端配置项: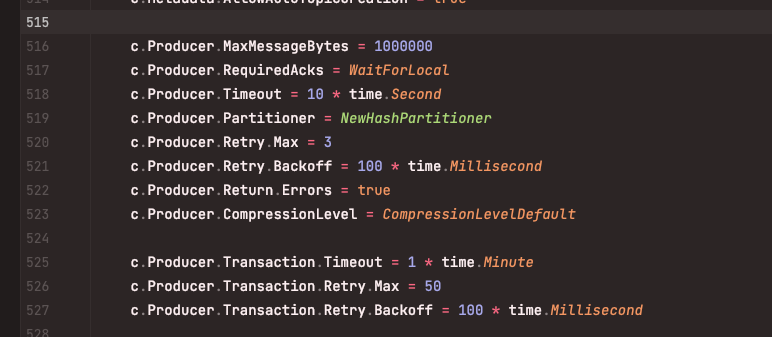
Broker 代理者
kafka服务,kafka集群中包含了>=1的kafka服务节点,每个节点都可以称为是一个broker.
kafka服务需要存储topic的消息,同时需要服务于consumer,由consumer拉取broker代理的消息
为了使得吞吐量最大化,topic的分区都会尽量平均到broker上,比如一个topic有10个分区,有5个broker,则每个broker都可以分到2个,如果没法平均分配,那就没得办法,会导致broker的资源利用不平均
consumer 消费者
消息的消费者,也是有程序员自身的业务服务实现,消费者消费时需要指定topic,partition,可以同时消费多个topic,消费多个topic的partition,但是不能同时消费一个partition的多个消息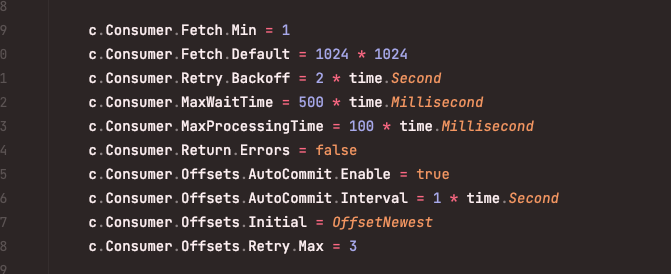
consumer group 消费组
假设你有10个进程,需要同时消费1个topic的10个分区消息,你会怎么写?
很明显,你可以每个进程配置一个partition分区进行消费,但是某个进程意外停止了呢?就会导致有个分区的消息一直没法消费
通过消费组,可以使得多个消费组组成一个群体,通过群体去进行动态的对分区进行平均分配: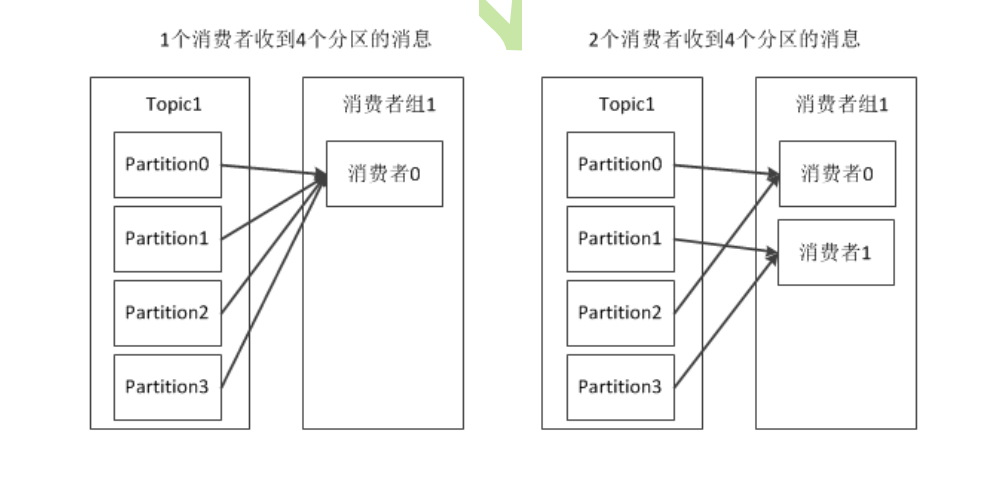
在稳定情况下,一个分区的消息只会被同一个消费组的消费组消费,在消费者数量发生变化后,将会重新分配分区的消费者绑定,这个情况叫做:rebalance
消费组 rebalance
当消费者组中消费者数量发生变化,或 Topic 中的 partition 数量发生了变化时,partition的所有权会在消费者间转移,即 partition 会重新分配,这个过程称为再均衡 Rebalance。再均衡能够给消费者组及 broker 集群带来高可用性和伸缩性,但在再均衡期间消费者是无法读取消息的,即整个 broker 集群有一小段时间是不可用的。因此要避免不必要的再均衡。
kafka的存储原理
安装好kafka,创建个主题,往主题下写入一些消息,在kakfa数据目录可以看到:
web_log-0,代表着 topic-partition 的文件夹
I have no name!@112fdbf94835:/bitnami/kafka/data/web_log-0$ ls
00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint partition.metadata
I have no name!@112fdbf94835:/bitnami/kafka/data/web_log-0$
再文件夹里面,分为3个文件: index(稀疏索引),log(消息数据存储),timeindex(时间索引),同时,0000000000000表示该分区的段文件,每到一定大小,将会拆分出多个段文件
图解如下: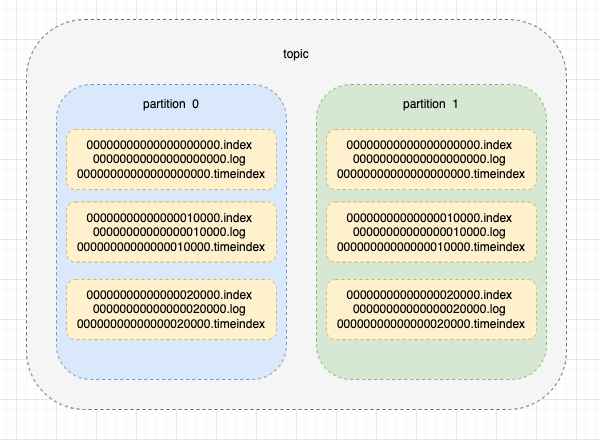
log结构
kafka的每条日志包含了1个标识消息长度的4字节整数N,接着是N字节的消息,比如对kakfa发送"this is a test log"消息,将会产生以下二进制文件,这里展示为16进制格式
00 00 00 00 00 00 00 00 00 00 00 4a 00 00 00 00
02 d1 2e ba b0 00 00 00 00 00 00 00 00 01 86 5d
8d f5 13 00 00 01 86 5d 8d f5 13 ff ff ff ff ff
ff ff ff ff ff 00 00 00 00 00 00 00 01 30 00 00
00 01 24 74 68 69 73 20 69 73 20 61 20 74 65 73
74 20 6c 6f 67 00
具体说明如下:
00 00 00 00 00 00 00 10 //消息的偏移值 8字节
00 00 00 4b //消息的总长度 4字节
00 00 00 00 //kafka领导选举自增 4字节
02 //魔术值为2 1字节
d1 2e ba b0 //crc校验码 4字节
00 00 //attributes 2字节 0-2位-压缩格式 3-时间类型,4事务,5-批次控制,6-高位水平线,其他未使用
00 00 00 00 //相对于前一条消息偏移量的差值 4字节
00 00 01 86 5d 8d f5 13 //消息集中最早的时间戳 8字节
ff ff ff ff ff ff ff ff //消息集中最晚的时间戳 8字节
00 00 00 00 00 00 00 01 //producer id
30 //生产者的 epoch,每个生产者的 epoch 都是独立的且会不断递增,它可以被用于实现幂等性,解决幂等性重复写入的问题。当生产者使用幂等性写入消息时,它会携带自己的 producerId 和 producerEpoch。Kafka 的 broker 会检查这些信息,并根据 producerId 和 producerEpoch 判断是否有重复的消息写入。 1字节
00 00 00 01 //事务消息序号 4字节
24 74 68 69 73 20 69 73 20 //key+value 消息的key和具体消息
61 20 74 65 73 74 20 6c 6f
67 00
index结构
kafka的index为b tree的稀疏索引类型,在磁盘中存储如下:
在index文件中,存储了消息的offset和具体的偏移值,通过偏移值可以在log文件中找到具体的消息:
I have no name!@112fdbf94835:/bitnami/kafka/data/web_log-0$ od -tx1 00000000000000000000.index
0000000 00 00 00 2e 00 00 10 35 00 00 00 5b 00 00 20 8e
0000020 00 00 00 88 00 00 30 e7 00 00 00 b5 00 00 41 40
0000040 00 00 00 e2 00 00 51 99 00 00 01 0f 00 00 61 f2
0000060 00 00 01 3c 00 00 72 4b 00 00 01 69 00 00 82 a4
0000100 00 00 01 96 00 00 92 fd 00 00 01 c3 00 00 a3 56
0000120 00 00 01 f0 00 00 b3 af 00 00 02 1d 00 00 c4 08
0000140 00 00 02 4a 00 00 d4 61 00 00 02 77 00 00 e4 ba
0000160 00 00 02 a4 00 00 f5 13 00 00 02 d1 00 01 05 6c
0000200 00 00 02 fe 00 01 15 c5 00 00 03 2b 00 01 26 1e
0000220 00 00 03 58 00 01 36 77 00 00 03 85 00 01 46 d0
0000240 00 00 03 b2 00 01 57 29 00 00 03 df 00 01 67 82
0000260 00 00 04 0c 00 01 77 db 00 00 04 39 00 01 88 34
0000300 00 00 04 66 00 01 98 8d 00 00 04 93 00 01 a8 e6
0000320 00 00 04 c0 00 01 b9 3f 00 00 04 ed 00 01 c9 98
- 前8字节:消息偏移量
- 4字节:对应消息所在数据文件的起始字节偏移量
- 4字节:消息长度 (可以看出都是8370长度
index文件并没有存储所有的索引,而是采用稀疏索引方式,跨多个offset存储
timeindex结构
timeindex文件用于对日志使用时间筛选时的索引方案
I have no name!@112fdbf94835:/bitnami/kafka/data/web_log-0$ od -tx1 00000000000000000000.timeindex
0000000 00 00 01 86 5e 56 60 23 00 00 00 2e 00 00 01 86
0000020 5e 56 60 ea 00 00 00 5b 00 00 01 86 5e 56 61 ae
0000040 00 00 00 88 00 00 01 86 5e 56 62 6c 00 00 00 b5
0000060 00 00 01 86 5e 56 63 28 00 00 00 e2 00 00 01 86
0000100 5e 56 63 e7 00 00 01 0f 00 00 01 86 5e 56 64 a5
0000120 00 00 01 3c 00 00 01 86 5e 56 65 62 00 00 01 69
0000140 00 00 01 86 5e 56 66 1d 00 00 01 96 00 00 01 86
0000160 5e 56 66 d1 00 00 01 c3 00 00 01 86 5e 56 67 85
0000200 00 00 01 f0 00 00 01 86 5e 56 68 38 00 00 02 1d
0000220 00 00 01 86 5e 56 68 e7 00 00 02 4a 00 00 01 86
0000240 5e 56 69 97 00 00 02 77 00 00 01 86 5e 56 6a 40
0000260 00 00 02 a4 00 00 01 86 5e 56 6a ea 00 00 02 d1
0000300 00 00 01 86 5e 56 6b ac 00 00 02 fe 00 00 01 86
0000320 5e 56 6c 64 00 00 03 2b 00 00 01 86 5e 56 6d 1a
0000340 00 00 03 58 00 00 01 86 5e 56 6d cb 00 00 03 85
0000360 00 00 01 86 5e 56 6e 7a 00 00 03 b2 00 00 01 86
0000400 5e 56 6f 27 00 00 03 df 00 00 01 86 5e 56 6f cf
0000420 00 00 04 0c 00 00 01 86 5e 56 70 6d 00 00 04 39
0000440 00 00 01 86 5e 56 71 13 00 00 04 66 00 00 01 86
0000460 5e 56 71 bb 00 00 04 93 00 00 01 86 5e 56 72 5c
0000500 00 00 04 c0 00 00 01 86 5e 56 72 f6 00 00 04 ed
0000520 00 00 01 86 5e 56 73 95 00 00 05 1a 00 00 01 86
8字节:时间戳
4字节:相对偏移量
kafka写入日志操作
kafka通过producer写入消息
producer会对消息进行缓存,一次性批量发送到broker中
同时在broker中,会通过mmap 方式,内存映射磁盘,进行顺序写入,每当到一定时间,或者写入消息多少条会进行一次落盘,真实存储到磁盘中
所以,在kafka中,如果突然崩溃,会丢失当前时间内,或者当前时间内还在写入的消息(因为没有落盘)
写入到日志文件
- 首先先通过topic,partition定位一个broker(每个broker存储了不同的分区数据)
- 定位到broker之后,根据topic+partition文件夹找到具体的segment文件
- segment文件如果已经超过1G(可配置),则根据offset创建一个新的segement文件
- 开始追加文件写入
为了避免每个消息都造成一个io读取消耗,使用的是mmap 方式,当到达一定消息量才开始真正落盘
kafka 读取日志操作
在读取前,我们会有一个8字节64位的偏移量,以及本身kafka设定的消息最大字节数,对日志进行读取.例如3333
- topic+partition文件夹定位
- 根据自己的offset偏移量,对文件名排序的文件进行2分查找(segment文件名带上了文件的第一条偏移量) 假设是0000000000.index和000001100000.index,那很明显,直接用0000000000.index
- 找到index文件,index文件采用了B tree方式存储,可以快速的找到一个范围内的offset+偏移量文件,假设是3000->偏移量,5000->偏移量
- 根据offset+偏移量,直接定位到文件中的offset,开始进行查找,根据3000偏移量直接定位到文件的3000存储位置,开始往后查找,直到找到数据
零拷贝sendfile
在准确定位到文件offset之后,可以获取到文件的offset,消息长度,偏移量等,通过sendfile零拷贝机制,节省io时间,直接发送给消费者
kafka删除
由于kafka是文件追加方式写入,是不能删除正在使用中的文件,但是当kafka消息积压到一定大小后,partition将会分段,分为多个段文件,日志管理器允许删除时间超过N天以上,保留NG的数据.
端对端批量压缩
为了节省带宽,kafka的生产者和消费者客户端都支持了压缩功能,可以使得发送的消息进行压缩,直接在broker压缩存储,只有被消费者pull之后,才会开始实际解压获取数据
数据准确性
每个消息都有一个crc校验码,可以进行消息验证,在写入磁盘时可能出现数据损坏,或者写入中断的情况下,kafka会对最新的消息日志进行迭代,验证crc,找到最新的crc消息段,删除往后的数据
消息发送的可靠性机制
生产者向broker发送消息时,可以选择不同的可靠级别.
- 0 生产者不会等待服务器确认,默认就是将消息添加到socket缓冲区,认为发送成功
- 1 broker的partition leader节点会将日志写入到本地日志,不等待其他节点响应,告诉生产者发送成功
- -1 broker的partition leader节点会等到所有副本确认到消息,才会返回发送成功
默认为-1值
消息消费的可靠性机制
消息消费也分为3个场景
- At-least-once(最少一次) 如果生产者可靠级别为-1,此时需要等待broker所有副本写入日志并返回成功,但是生产者网络异常没有获取到成功值,则会继续发送一条,此时会发送多条
- At-most-once(最多一次) 生产者忽略了broker的消息确认,只发送一次,当broker出问题时,将会丢失这条消息
- Exactly-once(精确一次) 生产者和消费者都得保证以下情况,生产者必须保证数据到达服务端(最少一次),消费者必须保证所有消息都消费到(忽略重复消息,需要定义业务消息唯一id,幂等)
kafka 分布式
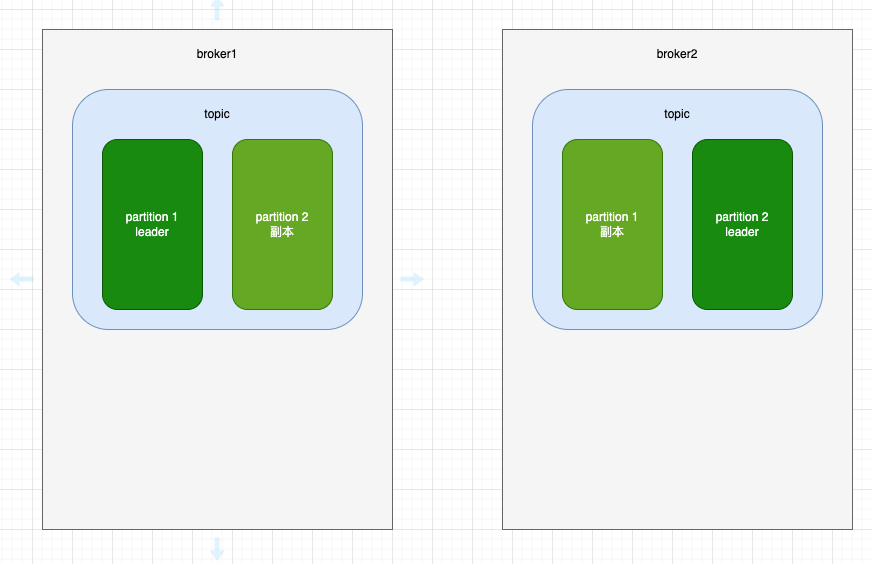
kafka通过partition为单位来做leader节点,一个节点可能是多个partition leader,多个节点可能是不同partition leader节点.
每个partition只会有一个leader节点,leader节点负责partition的读写,如果存在partition副本,该副本只作为备份使用,当leader节点出现异常时,副本节点就会成为leader节点负责该partition的读写
- 本文标签: 数据库
- 本文链接: https://www.php20.cn/article/420
- 版权声明: 本文由仙士可原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐

相关文章
近期评论
-
来自: 留言板
-
来自: 如何策划一个模拟经营类的文字游戏
-
来自: 留言板
-
来自: 留言板
-
来自: 留言板
