时序数据库学习三:数据模型
基于标签(tag-value)的时序数据模型
当前主流TSDB的时序数据模型都是以标签(tag 或者称为label) 为主来唯一确定一个时间序列(一般也附加上指标名称,时间戳等).
Pronmentheus时序数据模型
prometheus采用了多维数据模型,包含 指标名称(metric name),一个或多个标签(labels) 以及指标数值(metric value)
时序数据模型包括了 metric name,一个或多个labels,metric value
通过metric name加一组labels作为唯一标识,定义时间线(time series)
prometheus的指标模型定义如下:
<metric name>{<label name>=<label value> ...}
指标名称(metric name):
表示了被测系统的一般特征,即一个可以度量的指标
它采用了普遍的名称来描述一个时间序列,例如:sys.cpu.user,http_requests_total
标签(label):
由prometheus的维度数据模型来支撑实现.相同指标名称的任何给定标签组合标识该指标的特定维度实例
更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列.可以通过标签让查询语言轻松过滤,分组,匹配
样本(sample):
按照某个时序以时间维度采集的数据称为样本.
实际的时间序列,每个序列包括一个float64的值和一个毫秒级的unix时间戳,本质上属于单值模型.
单值模型的时间序列/时间线(time series): 具有相同指标名称和相同标签维度集合的带有时间戳数值的数据流。通俗地讲,就是用metric name加一组labels作为唯一标识,来定义时间线。
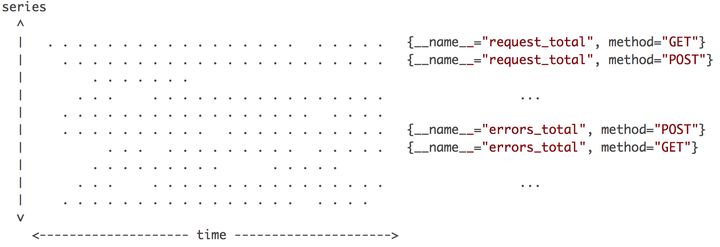
上图是某个时间段内的相关数据点的分布示意图,其中横轴是时间,纵轴是时间线,区域内每个点就是数据点。指标名称和一组标签唯一确定一条时间线(就是每条水平线)。在同一时刻,每条时间线只会产生一个数据点,但同时会有多条时间线产生数据,把这些数据点连在一起,就是一条竖线。因此,Prometheus每次接收数据,收到的是图中纵向的一条线。这些水平线和竖线的特征很重要,影响到数值插值,以及数据写入和压缩的优化策略。
InfluxDB时序数据模型
下图4是InfluxDB对时序数据模型的图形化表示:

图4
measurement:
指标对象,也即一个数据源对象。每个measurement可以拥有一个或多个指标值,也即下文所述的field。在实际运用中,可以把一个现实中被检测的对象(如:“cpu”)定义为一个measurement。measurement是fields,tags以及time列的容器,measurement的名字用于描述存储在其中的字段数据,类似mysql的表名。
tags:
概念等同于大多数时序数据库中的tags, 通常通过tags可以唯一标示数据源。每个tag的key和value必须都是字符串。
field:
数据源记录的具体指标值。每一种指标被称作一个“field”,指标值就是 “field”对应的“value”。fields相当于SQL的没有索引的列。
timestamp:
数据的时间戳。在InfluxDB中,理论上时间戳可以精确到 纳秒(ns)级别
每个Measurement内的数据,从逻辑上来讲,会组织成一张大的数据表(如下图5)。Tag用于描述Measurement,而Field用于描述Value。从内部实现来上看,Tag会被全索引,而Filed不会。
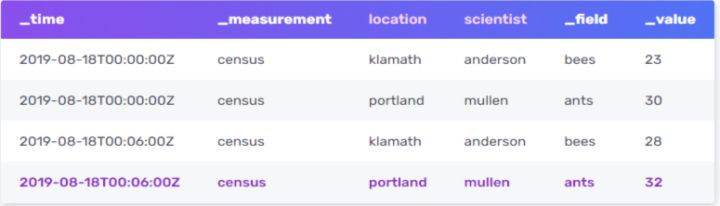
图5
多值模型下的时间线(Series):在讨论Series之前,先看看一个series key的定义:共享measurement,标记集合和field key的数据点的集合。它是InfluxDB的核心概念之一。比如上图中,census,location=klamath,scientist=anderson bees构成一个series key。因此上图中有2个series key。而Series就是针对给定的series key对应的时间戳和字段值。比如上图中,series key为census,location=klamath,scientist=anderson bees的series就是:
2019-08-18T00:00:00Z 23
2019-08-18T00:06:00Z 28
所以,InfluxDB中的series key可以理解为我们通常所说的时间线(或者时间线的key),而series就是时间线所包含的值(相当于数据点)。二者都泛指TSDB中的时间序列/时间线,只是从key-value对的角度进行了逻辑概念区分。
小结:如下图6所示,时序数据一般分为两部分,一个是标识符(指标名称、标签或维度),方便搜索与过滤;一个是数据点,包括时间戳和度量数值。数值主要是用作计算,一般不建索引。从数据点包含数值的多少,可以分为单值模型(比如Prometheus)和多值模型(比如InfluxDB);从数据点存储方式来看,有行存储和列存储之分。一般情况下,列存能有更好的压缩率和查询性能。
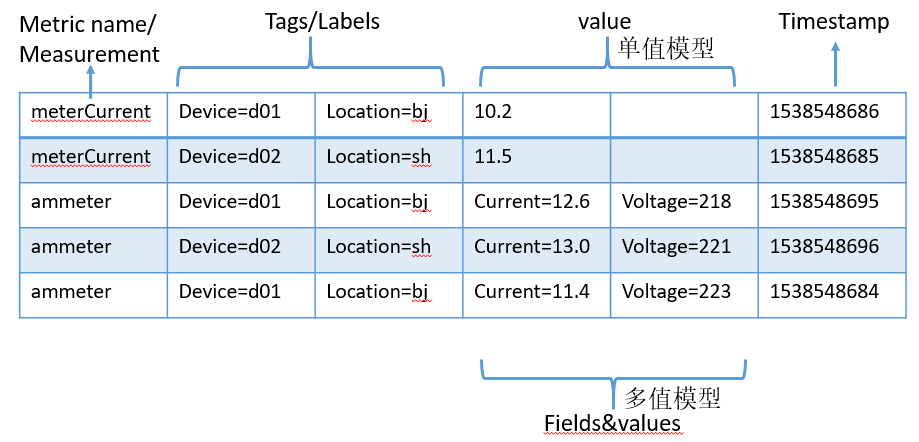
图6
基于树形(tree schema)的时序数据模型
IoTDB与其他TSDB的数据模型最大的不同,没有采用标签(tag-value、Labels)模式,而是采用树形结构定义数据模式:以root为根节点、把存储组、设备、传感器串联在一起的树形结构,从root根节点经过存储组、设备到传感器叶子节点,构成了一条路径(Path)。一条路径就可以命名一个时间序列,层次间以“.”连接。如下图7所示[8]:
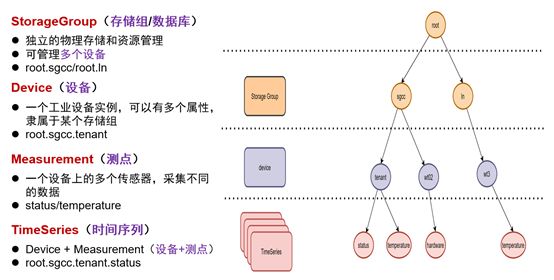
图7
数据点(Data point):一个“时间-值”对。
时间序列(一个实体的某个物理量对应一个时间序列,Timeseries,也称测点 meter、时间线 timeline,实时数据库中常被称作标签 tag、参数 parameter):一个物理实体的某个物理量在时间轴上的记录,是数据点的序列。类似于关系数据库中的一张表,不过这张表主要有时间戳(Timestamp)、设备ID(Device ID)、测点值(Measurement)三个主要字段;另外还增加了Tag和Field等扩展字段,其中Tag支持索引,Field不支持索引。
IoTDB这种基于树的模式(tree schema)和其它TSDB很不一样,有以下优点:
-
设备管理是层次化的:比如许多工业场景里设备管理不是扁平的,而是有层次的。其实在应用软件体系中也是类似的场景,比如CMDB就维护着软件组件或资源之间的一种层次关系。所以IoTDB认为基于tree schema 比基于 tag-value schema更合适IoT场景。
-
标签及其值的相对不变性:在大量实际应用中,标签的名字及其对应的数值是不变的。例如:风力发电机制造商总是用风机所在的国家、所属的风场以及在风场中的 ID 来标识一个风机,因此,一个 4 层高的树(“root.the-country-name.the-farm-name.the-id”)就能表示清楚,而且很简洁;一定程度减少了数据模式的重复描述。
-
灵活查询:基于路径的时间序列 ID 定义,比较方便灵活的查询,例如:”root..a.b.“,其中、*是一个通配符。
各TSDB的概念对比
首先从RDB视角来对比映射主流TSDB的基本概念,以方便大家理解。
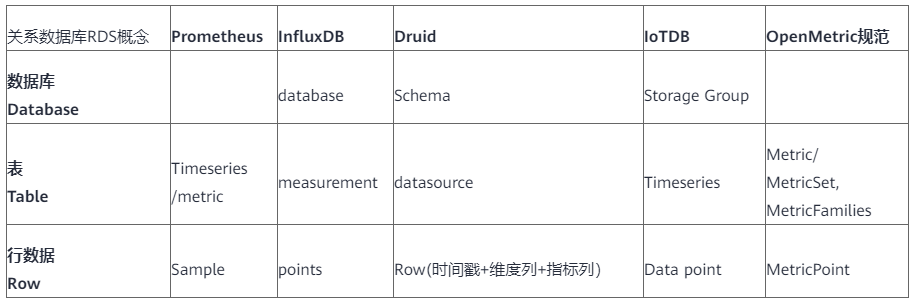
表1
从上面表1可以看出,database逻辑概念更多地体现了一种数据schema定义,方便数据的逻辑组织划分(比如InfluxDB的database)、管理(比如Druid的3种schema定义)和存储(比如IoTDB的storage group)。另外OpenMetric属于指标规范,更多地体现关于数据点的定义和逻辑细节的管理(比如MetricSet、MetricFamilies、MetricPoint、LabelSet等,搞得很细也很复杂)。
其次,我们从时序数据集中的每个数据点或者一行数据的角度来分析,以下图8为例。
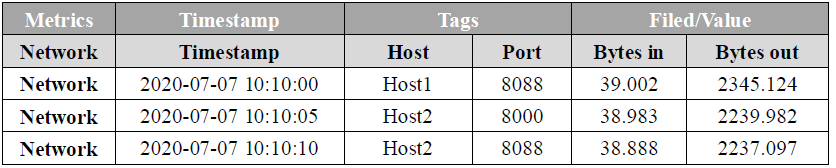
图8
时序数据的基本模型可以分成下面几个部分:
Metric:度量的数据集,类似于关系型数据库中的 table,是固定属性,一般不随时间而变化
Timestamp:时间戳,表征采集到数据的时间点
Tags:维度列,用于描述Metric,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化
Field/Value:指标列,代表数据的测量值,可以是单值也可以是多值
围绕上述时序数据模型,我们对比看看各种TSDB中基本概念的对应关系,如下表2所示:
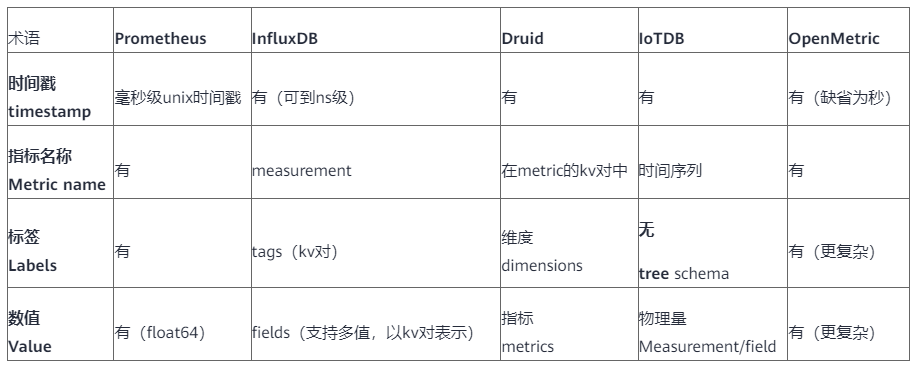
表2
本文参考:https://zhuanlan.zhihu.com/p/410255386
热门推荐

相关文章
近期评论
-
来自: 留言板
-
来自: 如何策划一个模拟经营类的文字游戏
-
来自: 留言板
-
来自: 留言板
-
来自: 留言板
