mysql的索引
在大部分情况下,程序的瓶颈都在于数据库,所以为了减少数据库的压力,我们会通过缓存(减少数据库查询),分布式数据库,读写分离等方式去减少数据库本身的curd压力.
但是,数据库还是避免不了一定要被程序curd的命运,而大部分压力来自于数据库的查询.
当不能避免查询数据库,该怎么优化数据库的查询速度呢?
没错,只有索引.
索引的好处
数据库索引是一个非常重要的东西,举个例子,
我们要去图书馆找一本<<php从入门到精通>>,最傻逼的做法就是从门口开始,一本一本看过去,直到找到这本书,有索引之后呢?
我们首先从图书馆分类开始:"外语","哲学","艺术","经营","少儿","计算机",通过"计算机"分类,指引我们到了一片区域,然后通过"A_Z"的书本名排序,我们很快就能定位到这本书,这就是索引
首先,我们建立个表:
create table \`article\`
(
\`id\` int auto_increment primary key comment 'id',
\`user_id\` int(11) not null comment '用户id',
\`title\` varchar(64) not null comment '标题',
\`add_time\` datetime comment '新增时间',
\`update_time\` int(11) comment '更新时间',
\`content\` text comment '内容',
\`description\` varchar(255) comment '简介',
\`status\` tinyint(1) comment '状态 1正常 0隐藏'
)engine = INNODB charset ='utf8'
我们用程序批量创建10w条数据用于测试(本文使用easyswoole程序创建):
<?php
include "./vendor/autoload.php";
\EasySwoole\EasySwoole\Core::getInstance()->initialize();
for ($i = 0; $i <= 1000; $i++) {//协程最多3000,创建1000个协程
go(function () use ($i) {
\App\Utility\Pool\MysqlPool::invoke(function (\App\Utility\Pool\MysqlObject $mysqlObject) use ($i) {
for ($y = 0; $y <= 100; $y++) {//每个协程插入100条数据
$data = [
'user_id' => mt_rand(1, 2500),
'title' => \EasySwoole\Utility\Random::character(32),//随机生成32位字母的标题
'add_time' => date('Y-m-d H:i:s', mt_rand(strtotime('2018-01-01'), strtotime('2019-01-01'))),//随机生成日期
'update_time' => mt_rand(strtotime('2018-01-01'), strtotime('2019-01-01')),//随机生成日期
'content' => getChar(mt_rand(100, 1024)),//随机生成100-1024位汉字,
'description' => getChar(mt_rand(8, 64)),//随机生成8-64位汉字,
'status' => mt_rand(0, 1),
];
$mysqlObject->insert('article', $data);
}
echo "协程$i 插入完成\n";
}, -1);
});
}
function getChar($num) // $num为生成汉字的数量
{
$b = '';
for ($i = 0; $i < $num; $i++) {
// 使用chr()函数拼接双字节汉字,前一个chr()为高位字节,后一个为低位字节
$a = chr(mt_rand(0xB0, 0xD0)) . chr(mt_rand(0xA1, 0xF0));
// 转码
$b .= iconv('GB2312', 'UTF-8', $a);
}
return $b;
}
大概需要等半个小时左右才能插入好10W条(固态硬盘快的飞起,为了测试慢的情况,所以没用固态)

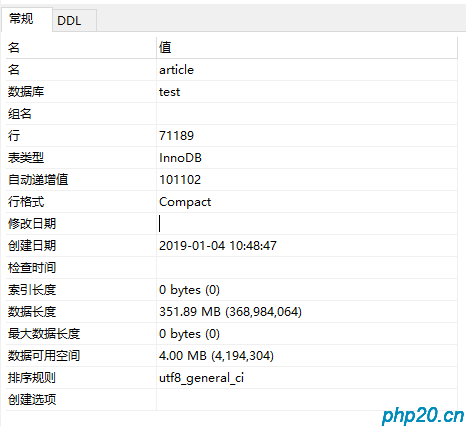
好的,我们已经插入了10W条数据,现在是除了id都是没有索引的,我们先查询下user_id=200的数据:
可以看到,查询一次数据需要5秒左右,这个速度在线上网站是会造成服务器崩溃的,用户根本没法正常访问网站,
在这个时候,索引的优势就出来了,我们给user_id增加一个索引:
ALTER TABLE \`article\`
ADD INDEX \`index_user_id\` (\`user_id\`) ;
由于数据量较大,第一次增加索引需要时间(索引时间根据字段基数,表数据大小而不同):

我们再一次查询:

很明显速度快了很多,索引在表数据越大的时候越能体现用处
索引类型
mysql的索引类型分为以下几种:
-
普通索引
-
组合索引
-
唯一索引
-
主键索引
-
全文索引
我们根据不同的业务需求,去使用不同的索引,提高查询速度.
普通索引
普通索引,顾名思义,就是普通的索引,没有其他特性,直接创建就可以使用
组合索引
组合索引是通过多个字段组合起来的索引,
主键索引
主键索引就是数据表的主键,主键是为了区分一个表中不同的数据列而产生的,
主键将确定表数据的实体,例如通过主键,我们才能定位到表数据的某一列,
如果一个表没有主键,那么这个表就没有什么意义,
主键可以是多个字段组成的,也可以是一个字段组成的,例如"id","member_name,member_code"等等,但一个表只能有一个主键,每个主键都是唯一的,不可能出现重复的字段
唯一索引
唯一索引增加了对索引值的约束,代表着该值只能出现一次,不能重复插入,
主键是特殊的唯一索引
唯一索引值可以为多个null,null代表没有存值,也就是null没有走索引
全文索引
全文索引是mysql的另一种技术
原理是先定义一个词库,然后在文章中查找每个词条(term)出现的频率和位置,把这样的频率和位置信息按照词库的顺序归纳,这样就相当于对文件建立了一个以词库为目录的索引,这样查找某个词的时候就能很快的定位到该词出现的位置。
本人不建议使用全文索引,请自行用php等分词技术做分词,并使用elasticsearch搜索引擎进行全文搜索
- 本文标签: 数据库
- 本文链接: https://www.php20.cn/article/166
- 版权声明: 本文由仙士可原创发布,转载请遵循《署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)》许可协议授权
热门推荐

相关文章
近期评论
-
来自: 留言板
-
来自: 如何策划一个模拟经营类的文字游戏
-
来自: 留言板
-
来自: 留言板
-
来自: 留言板
